Why you need to pay attention to OOMs
Ever wondered what powers AI's leap from basic chatbots to expert-level agents? It's all about OOMs—Orders of Magnitude.


Imagine this: it’s 2019, and the tech world is buzzing about GPT-2, an AI model that can write stories—sometimes coherent, sometimes wildly fantastical. Fast forward four years, and GPT-4 enters the scene. It's like comparing a preschooler who strings together a cute but nonsensical story to a sharp high-schooler capable of complex essays, solving math problems, and writing code. What changed in those few years? The answer is found in an unassuming concept called Orders of Magnitude (OOMs).
What exactly are OOMs (Orders of Magnitude)?
In plain terms, one OOM represents a 10x increase in whatever is being measured. In AI, this often refers to compute power, algorithmic efficiency, or the sophistication of training techniques. OOMs are the secret sauce that has pushed AI from generating quirky sentences to passing AP exams and becoming integral to our daily work tools.
In the AI race, counting OOMs helps us understand not just where we are but where we’re headed. It's how those “in the know” have managed to predict the revolutionary capabilities of models like GPT-4 and beyond.
A brief history of OOMs in AI
To understand the evolution of AI through OOMs, we need to take a broader look at how training compute has shaped this journey. A slow yet steady growth in compute power from the 1950s, with early milestones like the Perceptron Mark I, to significant improvements in the 2010s. The deep learning era, marked by models such as AlexNet and Word2Vec, set the stage for an explosive increase in compute use, accelerating at an estimated 4x/year since 2010, kicking of the deep learning era.
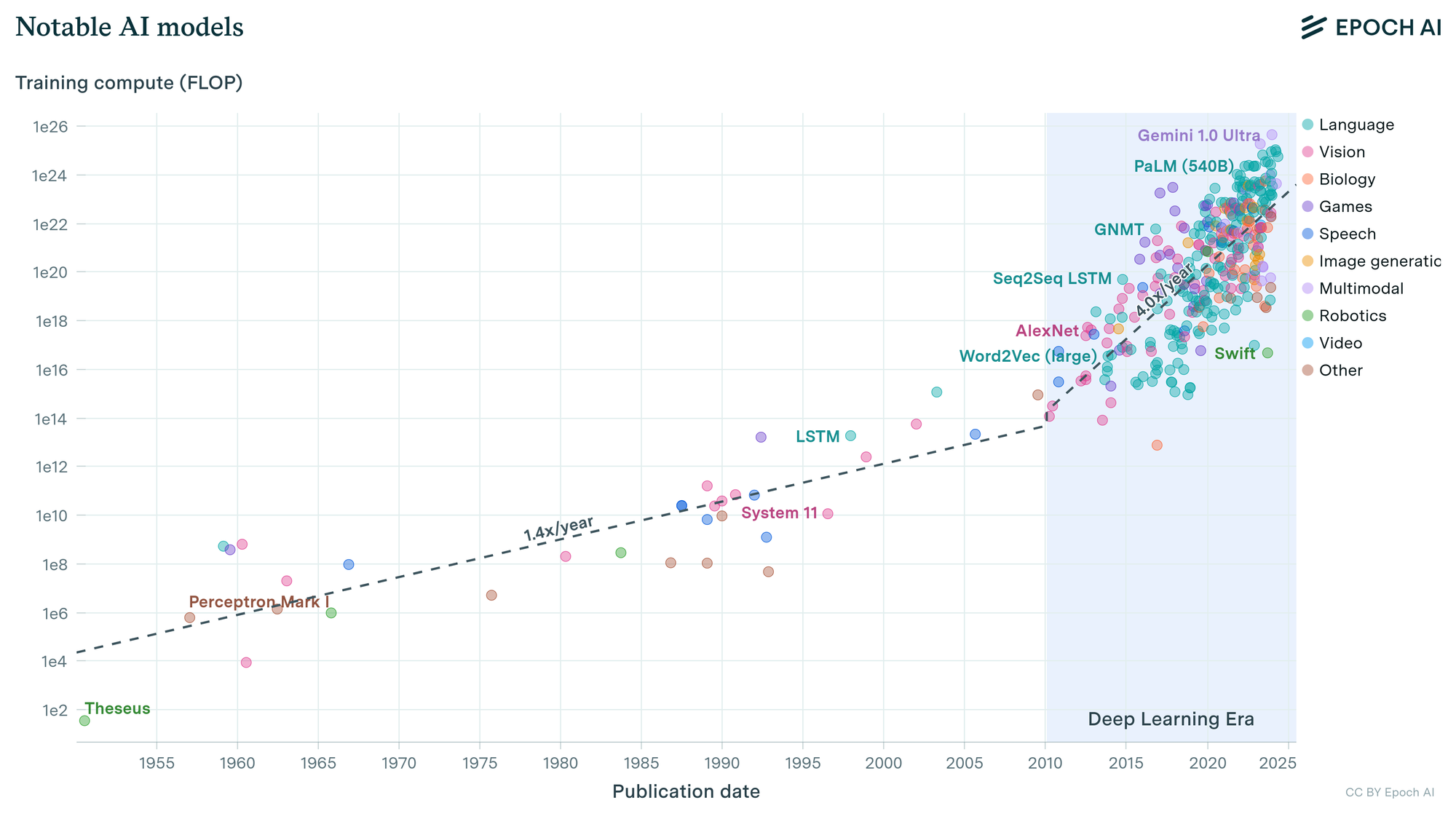
In 2019, GPT-2 emerged as an impressive model capable of writing short stories or answering basic questions, though often imperfectly. It was a product of the then-consistent trendline in compute power and algorithmic refinement. By 2020, GPT-3 leveraged the scaling laws visible in the chart, boasting improved language fluency that elevated it from a playful child-like AI to an elementary schooler capable of drafting emails or generating marketing content.
The major leap arrived with GPT-4 in 2023, a testament to the rapidly climbing OOMs depicted on the chart. This model showcased an unprecedented level of reasoning and problem-solving, outperforming most humans in standardized tests and excelling in complex coding tasks. Each stage, illustrated in the chart, underscores how incremental orders of magnitude in compute have driven AI from its early, simple origins to the sophisticated, multitasking agents we see today.
The jump wasn’t enabled by magic; it was a relentless march of OOMs—orders of magnitude in compute and algorithmic gains that scaled up the intelligence of these models.
How do OOMs drive progress?
Think of AI development as a tree. Compute power is the trunk, sturdy and central, while algorithmic efficiencies and training improvements are the branches that allow it to spread outward. Here’s how each plays a role:
- Compute Scale-Up: The most straightforward way to grow an AI model’s capabilities is by throwing more computing power at it. During the transition from GPT-2 to GPT-4, we saw a jump of around three OOMs in raw compute power. It’s akin to going from a decent desktop computer to thousands of interconnected GPUs humming in unity.
- Algorithmic Efficiencies: But raw power isn’t everything. Algorithms act as the unsung heroes, ensuring that models learn more from less. From 2019 to 2023, enhancements in algorithmic design contributed another 1-2 OOMs, making it possible for models to work smarter, not just harder.
- Training Techniques: Enter the realm of “unhobbling,” where AI models are tweaked to reach their potential. Simple innovations like chain-of-thought prompting allow a model to solve complex problems step by step, while tools like reinforcement learning from human feedback (RLHF) make models much more user-friendly and practical. These techniques are the leaves on our AI tree—essential for flourishing.
That’s all fascinating, but why should I care?
Because these leaps in OOMs directly translate to real-world impacts. Just a few years ago, AI could summarize articles or draft simple emails. Now, thanks to a handful of OOMs, it’s drafting entire research papers, debugging code, and aiding professionals in specialized fields.
In my own experience, I’ve seen AI progress from a tool that needed close monitoring to a near-indispensable partner. The promise? An AI coworker that can handle tedious tasks, draft documents, and even suggest solutions to complex problems.
The Challenges: Not All is Smooth Sailing
Yet, this OOM-driven acceleration isn’t without hurdles. One pressing issue is the looming data wall. As more powerful models require increasingly diverse and complex training data, we’re running out of readily available, high-quality internet data. This means AI labs need to get creative—through synthetic data, self-play, or reinforcement learning approaches—to maintain progress.
Moreover, as we race through OOMs, ethical concerns and regulatory issues multiply. AI models that can reason and adapt like human experts bring both potential and peril. Ensuring they align with our values and safety standards is paramount.
OOMs Beyond the status quo
Looking ahead, the roadmap laid out by counting OOMs is both exhilarating and daunting. By 2027, many experts believe we could be talking about AI systems that don’t just help write code or answer questions, but those that act as agents. Agents capable of understanding context, planning tasks, and executing long-term goals independently.
The next great unlocks will involve teaching models to learn like we humans do: with an internal dialogue, revisiting problems, iterating solutions, and improving over time. This could mean agents that tackle weeks-long projects, digest entire libraries of information, or serve as experts in niche fields—all enabled by the next few OOMs.
So why count OOMs?
Because they tell you how far AI has come and, more importantly, how far AI is likely to go. For those watching closely, they are a the signal pointing toward a future where AI is not just a tool, but an indispensable colleague and creative partner.


